
Nicolas COHEN
LA NOTION DE GÈNE
Mémoire de maîtrise
Année 1998 - 1999
1. Le Gène : une portion d’acide nucléique déterminant un caractère
1.1. Le gène, une unité d’information à l’origine d’un caractère
1.1.1. L’étude de cultures bactériennes met en évidence la correspondance gène/caractère
1.1.2. L’étude de mutants auxotrophes met en évidence la correspondance gène/enzyme
1.2. Le gène est porté par un acide nucléique
1.2.1. Les expériences de Griffith et d’Avery montrent que l’ADN porte l’information génétique
1.2.2. Les acides nucléiques sont également porteurs de l’information génétique des virus (1952).
1.3. Les bases moléculaires de l’hérédité : l’ADN
2.1. Ŕ un gène correspond une ou plusieurs chaînes polypeptidiques
2.1.1. Une colinéarité entre gène et séquence polypeptidique (Yanofsky 1964)
2.2. Un gène peut être reproduit à l’identique et transmis fidèlement à la descendance
2.2.1. La réplication ou reproduction du gène : copie conforme
2.2.2. La fidélité de la réplication du gène en vue de sa transmission à la descendance
2.3.1. Un gène code toujours pour un ARN
2.3.2. L’existence de modifications pré et post-traductionnelles chez les Eucaryotes
2.3.3. L’expression d’un gène est contrôlée et amplifiée
3.2. Des mutations modifient le gène et créent de nouveaux allèles
4.1. Certains gènes ont la possibilité de se déplacer
4.1.1. Réarrangements sporadiques
4.1.2. Réarrangements programmés
4.2. Certains gènes sont à l’origine de cancers : virus et oncogènes
4.3. Le génie génétique et ses perspectives
Résumé :
Le gène est un concept qui a été élaboré au cours de ce siècle depuis la découverte des lois de l’hérédité de Mendel : il est l’unité de base de tout être vivant, il contient les informations de la vie, de l’espèce et de l’individu et est transmis à la descendance. Le gène a d’abord été considéré comme une molécule à l’origine des caractères phénotypiques (visibles). Avec les expériences réalisées entre 1928 et 1952, on a découvert que l’information génétique avait pour support un acide nucléique (ADN ou même ARN). En 1953, Watson et Crick présentent un modèle tridimensionnel de la molécule d’ADN. Cette information est identique, à quelques exceptions près, dans toutes les cellules d’un même organisme ; elle doit donc pouvoir être reproduite à l’identique : c’est la réplication. Les gènes sont à l’origine des protéines, et l’information doit être décodée en vue de l’expression : la traduction est un changement de langage ; elle fait passer d’un code à 4 lettres (nucléotides) à un code à 20 lettres (acides aminés). Mais si la réplication est fidèle, quelques rares erreurs (mutations) qui modifient l’ADN peuvent subsister et être conservées au cours des générations si elles déterminent un avantage sélectif : ceci est le moteur de l’évolution. Cependant il existe des remaniements de l’ADN programmés et non aléatoires : ce sont des modifications somatiques à l’origine des immunoglobulines. Avec les récentes découvertes de l’ADN mobile, des virus et des gènes responsables de cancers, nous sommes aujourd’hui capables d’accéder aux gènes, de les modifier et de remplacer l’évolution naturelle, lente, par une évolution artificielle plus rapide (transgenèse) dont les conséquences demeurent encore incertaines.

" La génétique, la science de l’hérédité, née avec le siècle a grandi avec lui. Tout a commencé au tournant du siècle avec la redécouverte des lois de Mendel. Depuis lors, s’est poursuivie une recherche inlassable pour tenter de comprendre ce qu’est un gène, son fonctionnement, ses propriétés. "
(François Jacob, prix Nobel de médecine).
Le gène est un concept biologique. Gène provient du grec (genos = origine, gene = engendrer). Mot utilisé par Johannsen en 1909 réunissant plusieurs résultats d’étude sur l’hérédité : Mendel et ses facteurs héréditaires, Weismann et les facteurs déterminants, Morgan et la théorie chromosomique). Le gène est l’unité de base de l’hérédité, fragment de matériel génétique, qui détermine une caractéristique particulière ou un ensemble de caractéristiques. Depuis la création du terme, la définition du gène n’a cessé d’évoluer et d’être remise en cause par les découvertes plus ou moins récentes telles que le cistron, l’épissage différentiel, l’editing, les éléments génétiquement transposables...
1. Le Gène : une portion d’acide nucléique déterminant un caractère
1.1. Le gène, une unité d’information à l’origine d’un caractère
1.1.1. L’étude de cultures bactériennes met en évidence la correspondance gène/caractère
Mendel, en 1865, avait appelé facteurs héréditaires les particules véhiculant l’information génétique. Aujourd’hui, on parle de gènes. Le mot gène fut utilisé en 1909 pour la première fois par Johannsen. L’étude sur les Drosophiles (Morgan) ou sur les bactéries montre qu’une information est transmise à la descendance et qu’elle s’exprime par des caractères particuliers. On nomme génotype l’information contenue dans les gènes et phénotype son expression. Les travaux sur une lignée d’Escherichia coli de phénotype connu ont permis d’obtenir des mutants ; les mutations étant alors transmissibles à la descendance. Toute modification du gène se traduit par une modification d’un ou plusieurs caractères.
1.1.2. L’étude de mutants auxotrophes met en évidence la correspondance gène/enzyme
Certains mutants obtenus à partir d’une souche sauvage prototrophe (pousse sur milieu minimum) peuvent être incapables de croître sur milieu minimum. Ils sont appelés auxotrophes. L’étude de ces mutants a été faite sur un champignon ascomycète : Neurospora crassa. C’est un champignon haploïde ce qui permet de connaître le génotype en observant son phénotype. Des mutants arginine– (Arg–) ont été sélectionnés : il faut leur fournir de l’arginine dans le milieu minimum pour qu’ils puissent croître. On a distingué différents mutants Arg– qui ont des comportements différents si on leur fournit non pas de l’arginine mais différents précurseurs de l’arginine : ornithine et citrulline. Certains mutants sont bloqués dans les phénomènes de conversion entre les précurseurs et l’arginine ; il s’agit donc de l’absence d’enzymes responsables du bon déroulement de la chaîne de biosynthèse de l’acide aminé.
Cependant, toutes les fonctions résultant de l’expression d’un gène ne sont pas obligatoirement dues à la synthèse d’une enzyme.
1.2. Le gène est porté par un acide nucléique
(Figure 1) En 1928, le microbiologiste anglais Griffith constata que l’injection de pneumocoques de type S (smooth = lisse) à des souris provoquait leur mort (1) tandis que l’injection de pneumocoques de type R (rough = rugueux) ainsi que celle de bactéries S (virulentes), inactivées par la chaleur laissaient les animaux indemnes (2) : bactéries non virulentes.
L’injection de bactéries R mélangées à des bactéries S inactivées provoqua la mort des souris (3). Des pneumocoques vivants de type S furent retrouvés dans le sang de ces souris.
Apparemment un facteur de virulence a été transmis des bactéries S mortes vers les bactéries R. C’est ce que Griffith appela le facteur transformant. Différentes hypothèses furent envisagées :
- Les bactéries R peuvent avoir subi une mutation réverse (fréquence de 10–8) or la transformation se fait à une fréquence de 10–3.
- Les bactéries R peuvent avoir appris à fabriquer les capsules des bactéries S : elles auraient reçu le gène de synthèse de la capsule.
Avery, Mc-Cleod et Mc-Carty ont démontré que la nature du facteur transformant était de l’ADN (Figure 2). Après avoir purifié l’extrait de bactéries S (dénaturation des protéines, lipides et polysaccharides), la capacité de transformation persistait (1 à 3).
Seul l’ADN (acide désoxyribonucléique) n’était pas dénaturé par la chaleur (4) et était intégré dans les cellules R par transformation avec une fréquence de 10–3 ce qui permettait l’obtention de cellules S à partir de cellules R.
1.2.2. Les acides nucléiques sont également porteurs de l’information génétique des virus (1952).
- Des expériences concernant un virus à ADN : le bactériophage
Hershey et Chase ont marqué les protéines de la capside de bactériophages au soufre radioactif 35S et leur ADN au phosphore radioactif 32P (Figure 3). Lors de l’infection de bactéries par ces phages, seul le 32P fut retrouvé dans les bactéries. La formation de nouveaux phages prouva que l’ADN était porteur de l’information génétique.
- Chez certains virus les gènes sont portés par de l’ARN
L’ADN n’est pas la seule molécule portant l’information génétique. En effet, certains virus ne possèdent pas d’ADN mais de l’ARN (acide ribonucléique) : ce sont les rétrovirus. Cependant, après l’infection d’une cellule, cet ARN est nécessairement retranscrit en ADN. Le matériel génétique demeure toujours un acide nucléique.
1.3. Les bases moléculaires de l’hérédité : l’ADN
En 1953, James Watson et Francis Crick proposent un modèle décrivant la structure de la molécule d’ADN. Il s’agit d’une structure en double hélice (Figure 4). L’étude de la molécule par diffraction des rayons X a permis de confirmer l’exactitude du modèle, mais aussi de montrer l’existence d’une diversité structurale de cette hélice. L’ADN est une molécule bicaténaire. La conformation spatiale se fait de telle sorte qu’une adénine et une thymine d’une part et une guanine et une cytosine d’autre part sont toujours face à face et tournées vers l’intérieur du squelette désoxyribose-phosphate. L’ADN constitue les chromosomes.

Les bases sont assemblées par liaisons faibles (liaisons hydrogène) : deux liaisons H sont présentes entre A et T et trois liaisons H entre G et C. Ces appariements sont les seuls possibles pour des raisons d’encombrement stérique ; les deux types de bases n’ayant pas la même taille, l’association de deux bases de petite taille ou au contraire de deux bases de grande taille perturberait la régularité de la double hélice. L’appariement et la réalisation de liaisons hydrogène entre deux bases complémentaires sont responsables de l’orientation opposée des molécules des deux brins d’ADN, qualifiées ainsi de chaînes antiparallèles. La configuration spatiale de la molécule est très importante pour son fonctionnement, elle protège les bases et permet toutefois l’exploitation du contenu de l’information génétique.
La notion de gène jusqu’en 1953 était affranchie de toute connaissance concernant l’ADN. Avec la découverte de la double hélice, hérédité et biochimie sont alors réunies : le gène est désormais une notion nucléaire. Il doit pouvoir être exprimé, régulé, répliqué fidèlement et transmis à la descendance. C’est à partir de cette molécule que sont synthétisés les ARN et les protéines de l’organisme.
2.1. Ŕ un gène correspond une ou plusieurs chaînes polypeptidiques
2.1.1. Une colinéarité entre gène et séquence polypeptidique (Yanofsky 1964)
Yanofsky a étudié la protéine A de la tryptophane synthétase d’E. coli. Il a étudié en parallèle des gènes mutés codant pour cette enzyme et des protéines altérées issues de ces mutations. Il existe une corrélation linéaire entre les sites mutationnels de l’ADN et les acides aminés modifiés : la séquence linéaire des nucléotides d’un gène détermine la séquence des acides aminés de la protéine. A un gène correspond une protéine fonctionnelle donnée.
Des tests de complémentation (Figure 5) ont été réalisés sur la levure dont on a isolé 6 souches [ad–] ne pouvant pousser que sur milieu minimum enrichi en adénine (mutants auxotrophes).
Il y a complémentation chez le diploïde [ad+] : les mutations affectent deux gènes différents et à l’issue de la méiose il peut y avoir crossing over formant des recombinés [ad+].
Il n’y a pas complémentation : les mutations affectent le même cistron. Ad3 et ad4 sont des homoallèles, leurs séquences sont juxtaposées ou peuvent se chevaucher. Lors de la formation de spores par méiose, il n’y a aucune recombinaison possible.
Il n’y a pas de complémentation : les mutations affectent un seul et même cistron. Lors de la formation des spores par méiose, il apparaît dans 0.01 % des cas des recombinés [ad+]. Il y a eu crossing over entre ad5 et ad6 dans très peu de cas car les deux séquences sont très proches sur le chromosome. Les deux séquences sont séparées mais appartiennent à un même cistron : ce sont des hétéroallèles. A la suite de ce crossing over on obtient des spores (ad5+ ad6+) et des spores (ad5– ad6–) qui pourront complémenter et former des diploïdes [ad+]. La complémentation a alors lieu en position cis au lieu de trans dans le 1er cas (origine du mot cistron).
Le cistron est un fragment de gène constituant une unité fonctionnelle. Actuellement, un cistron représente un segment d’ADN codant pour un polypeptide. Du point de vue fonctionnel, la signification du terme cistron se superpose à celle du terme gène.
L’hémoglobine (Figure 6) est constituée de quatre sous-unités : quatre chaînes polypeptidiques identiques deux à deux. L’hémoglobine HbA (adulte normale) présente chez l’adulte est constituée de deux chaînes a et deux chaînes b (a 2b 2). Dans certains cas, des mutations affectent le gène d’une chaîne : c’est le cas de la drépanocytose ou anémie falciforme. Il s’agit d’une pathologie due à une mutation du gène de la b globine ; au milieu du codon 6, l’adénine est remplacée par la thymine et l’acide glutamique correspondant au codon normal est remplacé par la valine. Ce simple changement a des conséquences physiopathologiques importantes, sévères chez les sujets homozygotes HbS (Sickle = faucille) et à évolution chronique.
2.2. Un gène peut être reproduit à l’identique et transmis fidèlement à la descendance
2.2.1. La réplication ou reproduction du gène : copie conforme
La réplication consiste à la reproduction de l’ADN en deux molécules identiques entre elles et identiques à la molécule mère. Chez E.coli, il existe trois ADN polymérases différentes dont les plus importantes sont les ADN polymérases I et III (Figure 7). L’ADN polymérase III assure la majeure partie de la polymérisation ; l’ADN polymérase I comble les espaces entre les fragments d’Okasaki. Il existe d’autres enzymes : télomérases, topo-isomérases, gyrases…
Les ADN polymérases ont également une fonction exonucléasique permettant une " correction sur épreuve ", c’est-à-dire une réparation de l’ADN simultanément à sa formation, en cas de mésappariements ou autres erreurs.
Chez les Eucaryotes, le principe reste le même. On connaît plus d’ADN polymérases : l’ADN polymérase a (initiation + réparation), l’ADN polymérase b (élongation + réparation), l’ADN polymérase g (mitochondrie), l’ADN polymérase d , mais aussi d’autres polymérases particulières (transférase terminale, Cm polymérase dans les cellules cancéreuses, transcriptase inverse dans les cellules infectées par les rétrovirus…).
2.2.2. La fidélité de la réplication du gène en vue de sa transmission à la descendance
Pendant la réplication, les ADN polymérases vérifient la validité de la base précédente avant d’en ajouter une autre : c’est la correction sur épreuve. Des appariements erronés peuvent néanmoins échapper à la correction sur épreuve : des altérations spontanées (désamination de la cytosine en uracile) ou des agressions par des produits naturels ou des radiations, peuvent modifier la double hélice après la réplication. La correction fait alors intervenir de nouvelles enzymes : les enzymes de réparation. Parmi les réparations couramment effectuées, on peut citer la suppression des dimères pyrimidiques qui se forment après une exposition au rayonnement ultraviolet.
Ces phénomènes de réparation sont très importants car ils permettent de conserver une certaine stabilité de l’ADN et de permettre aux gènes de rester fonctionnels et de pouvoir être exprimés.
2.3.1. Un gène code toujours pour un ARN
- Le gène est transcrit en ARN m, t ou r mais il existe des ribonucléoprotéines
La synthèse des protéines fait intervenir plusieurs ARN : des ARN messagers, intermédiaires qui véhiculent l’information entre l’ADN et les protéines, plusieurs types d’ARN ribosomaux et des ARN de transfert, qui participent à la mise en place ordonnée des différents acides aminés. Des séquences consensus ont été mises en évidence au niveau des promoteurs. La séquence consensus des gènes eucaryotes est voisine de la boîte Pribnow des procaryotes : boîte TATA (TATA box) dont le centre est situé en amont de 25 nucléotides du premier transcrit. En –75 nucléotides se trouve une boîte CAAT. De la même façon que pour la réplication, la transcription fait intervenir plusieurs ARN polymérases en fonction de l’ARN transcrit, et de nombreux facteurs de transcription. Chez les Procaryotes, il existe une seule ARN polymérase à plusieurs sous-unités dont la sous-unité s et reconnaît directement la séquence du promoteur. Chez les Eucaryotes, il existe trois ARN polymérases dont l’ARN polymérase II qui transcrit la plupart des gènes en ARNm (messager). Cette ARN polymérase nécessite des facteurs de transcription TFII (A à H) formant un complexe d’initiation (Figure 8).
Certains gènes ne possèdent pas de TATA box mais un initiateur différent et nécessitant l’intervention de protéines IBP (initiator binding protein). D’autres encore ne possèdent pas de TATA box ni d’initiateur. Dans ces cas-là il peut y avoir plusieurs origines de transcription.
Des facteurs d’élongation permettent la progression du complexe et la naissance d’un transcrit primaire. Comme l’initiation, la terminaison de la transcription est contrôlée précisément. Chez les Procaryotes, la transcription cesse lors de la rencontre de signaux comme une séquence palindrome riche en GC suivie d’une région riche en AT. Chez les Eucaryotes, il existe en plus des modifications post-transcriptionnelles.
D’autres gènes sont à l’origine des ARNr (ribosomaux) qui ne seront pas traduits en protéines mais s’assembleront avec des protéines pour former les ribosomes (Figure 9). D’autres encore seront transcrits en ARN t (de transfert) qui permettront la reconnaissance des triplets (codons) de l’ARNm mature pour fixer entre eux les acides aminés de la future protéine.
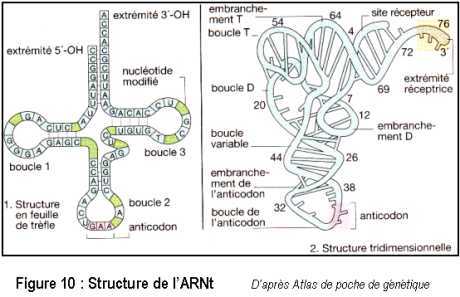
La structure de l’ARNt a été décrite sur la phénylalanine de la levure. Sa structure secondaire est caractéristique : en feuille de trèfle (Figure 10). Trois régions sont formées de boucles simple-brins. La structure tridimensionnelle de l’ARNt est complexe et permet de distinguer différents domaines, notamment le site de reconnaissance (anticodon) du codon de l’ARNm, et sur l’extrémité 3’, la zone de fixation par l’aminoacyl-ARNt-synthétase de l’acide aminé correspondant.
- Les ARNm issus de la transcription de certains gènes sont traduits en polypeptides
Les ARNm transcrits à partir des gènes sont ensuite traduits en protéines (Figure 11) grâce aux ARNt , r et aux différentes enzymes et facteurs intervenant dans cette synthèse. La traduction ne se fait pas au hasard, chaque codon correspond à un acide aminé particulier ou à un codon stop (message d’arrêt) : la traduction se déroule selon le code génétique, élucidé entre 1961 et 1968 par diverses équipes dont celle de Niremberg.
Pour les Procaryotes, l’ARNm n’est pratiquement pas modifié et du fait de l’absence d’enveloppe nucléaire, la traduction peut commencer tandis que la transcription n’est pas terminée. En revanche, chez les Eucaryotes, il existe de nombreuses modifications.
2.3.2. L’existence de modifications pré et post-traductionnelles chez les Eucaryotes
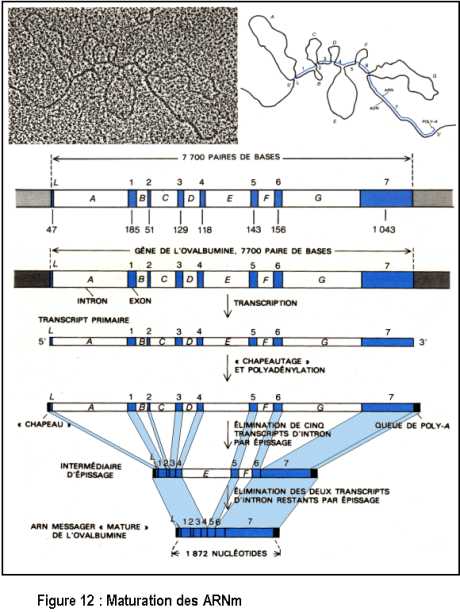
La maturation des ARN eucaryotes consiste, comme chez les Procaryotes, en une modification des extrémités des molécules, mais il s’y ajoute une étape d’excision-épissage de portions internes de l’ARNm. Ceci a été mis en évidence par la méthode d’hybridation entre l’ADN et l’ARNm cytoplasmique (Figure 12). Il y a donc excision de certaines parties nommées introns (restent à l’intérieur du noyau) et l’assemblage d’exons (sortent du noyau) : ce mécanisme se fait de façon très précise. De plus, après la transcription, les pré-ARNm (transcrits primaires) sont modifiés à leur extrémité 5’ par l’addition d’une coiffe guanosine terminale, méthylée et modifiée. Il y a addition également d’une queue polyadénylée (polyA). C’est sous cette forme que l’ARNm " mature " sort du noyau pour être traduit en protéine dans le cytoplasme.
2.3.3. L’expression d’un gène est contrôlée et amplifiée
- Chez les Procaryotes, la transcription des différents gènes d’un opéron est coordonnée
Chez les Procaryotes, les ARN polycistroniques permettent à plusieurs enzymes intervenant dans une même voie métabolique d'être produites simultanément. La régulation de l’expression d’un gène peut être positive (synthèse ou non de la protéine correspondante) ou négative et porte essentiellement sur la synthèse d'enzymes.
L'opéron lactose (Figure 13) chez les Procaryotes est soumis à une double régulation : négative et positive. Les gènes de structure qui codent les trois enzymes inductibles participant au métabolisme du lactose sont situés les uns derrière les autres et précédés d'un opérateur et d'un promoteur communs. L’ensemble forme un opéron précédé par un gène régulateur qui code un répresseur, petite protéine qui se fixe sur l'opérateur et qui empêche ainsi la transcription.
Ŕ cette régulation " négative " de l'opéron s'y ajoute une " positive ". En effet, lorsque le lactose et le glucose sont présents simultanément dans le milieu, les enzymes du métabolisme du lactose ne sont pas " induites " tant qu'il reste du glucose utilisable.
L'induction de l'opéron lactose n'est en fait possible qu'en présence d'un complexe constitué d'une protéine régulatrice CAP (catabolite gene activator protein) et d'une molécule d'adénosine monophosphate cyclique (AMP cyclique ou AMPC). La transcription est alors activée, car il se produit une meilleure fixation de l'ARN polymérase au promoteur.
Le fonctionnement de la protéine CAP est en relation directe avec la teneur cellulaire en AMPC directement dépendante de celle du glucose (la concentration en AMPC augmente lorsque le glucose vient à manquer). La cellule se met alors à utiliser davantage de lactose en activant l'opéron lactose. En revanche, en présence de glucose, l'induction de l'opéron lactose n'a pas lieu, car l'un des catabolites du métabolisme du glucose diminue le taux d'AMPC.
- Certains opérons sont contrôlés par atténuation
L'opéron tryptophane est un opéron dont les gènes de structure codent cinq protéines intervenant successivement lors de la biosynthèse du tryptophane (Figure 14).
La transcription à l'origine de l'ARNm polycistronique correspondant à ces cinq gènes peut être réprimée par un répresseur qui n'agit qu'en liaison avec le tryptophane : ce répresseur est qualifié pour cela de corépresseur. En présence d'une quantité élevée de tryptophane, la répression s'exerce ; en son absence, elle est levée.
Comme dans le cas de l'opéron lactose, il s'agit donc également d'une régulation négative, mais ici la fixation du répresseur à l'opérateur n'est possible que lorsque le répresseur est fixé au tryptophane, alors que le répresseur de l'opéron lactose ne peut plus se fixer à l'opérateur s'il est lié au lactose.
A cette interaction s'ajoute un contrôle supplémentaire, cette fois-ci par atténuation. Plus le tryptophane se raréfie et le plus le nombre d'ARNm entièrement transcrits augmente. L'intensité de la transcription est donc fonction de la quantité de tryptophane présent dans le milieu. En amont du premier gène de structure de l'opéron tryptophane se trouve une séquence de 161 nucléotides. Lors de sa transcription, deux séquences complémentaires situées vers son extrémité permettent la formation d'une boucle en épingle à cheveux suivie d'une séquence poly U. La transcription s'arrête donc au niveau de cette séquence particulière qualifiée d'atténuateur.
La séquence initiale de 161 nucléotides (leader) est en fait susceptible de former deux types de boucles en épingle à cheveux, une boucle 2-3 ou une boucle 3-4. Si la formation de la boucle 3-4, signal de terminaison, est contrariée, l'ARN polymérase poursuit sa progression et la transcription continue.
Quand la teneur en tryptophane du milieu est élevée, mais pas suffisamment pour que la transcription soit bloquée par le répresseur, la transcription donne naissance à la séquence leader de l'ARNm dont une partie est traduite, au fur et à mesure de la transcription, en un peptide de 14 acides aminés. La transcription de la séquence leader se poursuit au delà de la zone codant ce peptide, jusqu'à une deuxième zone du leader au niveau de laquelle la zone 2 de l'ARNm est bloquée par un ribosome. Ce blocage permet la formation de la boucle 3-4 de terminaison : la transcription cesse et les gènes de structure ne sont plus exprimés. Si la teneur en tryptophane est faible, le peptide leader ne peut être fabriqué faute de trpARNt chargé. Il reste bloqué au niveau du ribosome, en laissant le site 2 de la séquence leader s'apparier au site 3. La boucle de terminaison 3-4 ne peut alors se former et l'ARN polymérase peut accomplir la transcription de l'ARNm en entier : les cinq gènes de structure seront alors exprimés.
- Chez les Eucaryotes, il existe de nombreuses modalités de contrôle encore mal connues
Les complexes d'histones participent à la régulation des gènes, une région est active lorsqu'elle est fréquemment transcrite. Ces régions actives sont moins condensées qu'ailleurs et les nucléosomes y seraient dépourvus d'histones de condensation H1. Les gènes codant les ARN ribosomaux, qui sont donc les plus fréquemment transcrits, semblent se situer dans des régions dépourvues de nucléosomes. Les gènes " domestiques ", qui codent en permanence de nombreuses protéines de la vie cellulaire, sont eux aussi situés en dehors des nucléosomes : les boîtes TATA, indispensables à l'initiation de la transcription, sont donc toujours disponibles pour la fixation des facteurs de transcription. Les régions actives sont hypométhylées. Dans les génomes d’Eucaryotes, une grande partie des séquences CG possèdent un groupement méthyle sur le carbone 5 de la cytosine. Il est probable que les groupements méthyle, formant des saillies dans les cavités des sillons majeurs de la double hélice, modifient le positionnement des protéines régulatrices.
Certains facteurs de transcription restent liés au gène lors de la transcription. Le premier des facteurs de transcription à avoir été étudié est le facteur TATA (TFIID) qui se fixe sur la boîte TATA. Chaque domaine a la forme d'un doigt de gant et possède, lié à quatre acides aminés, un atome de métal, souvent de zinc, d'oů l'appellation doigt de zinc. L'extrémité de ces doigts s'adapte aux sillons majeurs ou mineurs de la double hélice. Ces domaines en doigts à métal ont été découverts dans de nombreuses protéines se liant à l'ADN ou à l'ARN, notamment dans les récepteurs des hormones stéroïdes. Ces hormones, après s'être liées à leurs récepteurs, agissent en stimulant la transcription. La majorité des gènes des Eucaryotes sont, comme ceux des Procaryotes, contrôlés par des promoteurs situés en amont des gènes mais aussi des éléments amplificateurs ou enhancers pouvant se fixer aux promoteurs
Le contrôle peut s’effectuer par une modification de la durée de vie des ARNm. On peut donner l'exemple des hormones stéroïdes qui sont capables d'augmenter la durée de vie des gènes dont elles ont, au préalable, stimulé la transcription. Il peut s’effectuer au cours de la traduction : certains mécanismes de contrôle agissent à différentes étapes de la traduction. Des protéines, en se liant à l'ARNm peuvent empêcher ou, au contraire, activer la traduction. Diverses substances peuvent agir sur les facteurs d'initiation de la traduction : par exemple, l'absence d'hème inhibe la synthèse d'hémoglobine en activant un inhibiteur qui bloque un facteur d'initiation de la synthèse protéique.
Quelques exemples d'épissage différentiel ou alternatif sont maintenant bien connus : on peut citer le gène de la calcitonine de rat qui, dans les cellules C de la thyroïde, est exprimé sous la forme de calcitonine, alors que dans le cerveau, il produit le CGRP ou calcitonine gene-related peptide (Figure 15).
On connaît depuis peu, un processus qui altère la correspondance entre ADN et ARNm : ce processus est appelé édition (editing) de l'ARN. La transcription produit un préARNm au niveau duquel il peut y avoir insertion ou délétion d'un ou de plusieurs nucléotides, ce qui peut changer plus ou moins profondément la séquence de la protéine. Ces phénomènes ont été souvent décrits chez des Trypanosomes, mais ils existent également chez des organismes supérieurs, végétaux ou animaux, notamment dans l'espèce humaine. Chez l'Homme, le gène codant l'apolipoprotéine B100, synthétisée dans le foie et intervenant dans le transport des lipides, peut également, après editing, donner naissance, cette fois dans l'intestin, à l'apolipoprotéine B48 plus courte que B100. L'editing, en remplaçant un nucléotide C par un U, a en effet fait apparaître un codon stop. On ne connaît pas les mécanismes de cette édition des ARN, mais ils doivent être génétiquement programmés ; ils ne s'effectuent en effet pas au hasard, puisque la séquence des protéines produites est toujours la même dans un organisme comme dans sa descendance.
Malgré cette très grande fidélité, des modifications du contenu des gènes apparaissent spontanément, rarement, de façon aléatoire et constituent le moteur de l’évolution.
Les remaniements génétiques sont de deux types : les remaniements interchromosomiques ont lieu lors de la répartition des chromosomes pendant la première ou la deuxième division de méiose ; et les remaniements intrachromosomiques (crossing-over) ont lieu pendant la prophase de première division (Figure 16). Ces remaniements ont donc lieu pendant la méiose, première étape de la reproduction sexuée. Un dernier brassage a lieu lors de la fécondation.
Les différentes combinaisons possibles de réorganisation du génome sont extrêmement nombreuses. Cependant, il existe en plus de ces remaniements, des modifications du génome.
3.2. Des mutations modifient le gène et créent de nouveaux allèles
La transcription et la traduction permettent le transfert de l’information génétique d’une séquence nucléotidique d’ADN vers une séquence correspondante d’acides aminés. Une altération (mutation) d’une séquence d’ADN peut provoquer une modification de cette séquence d’acides aminés correspondante. Une mutation est un événement rare, apparaissant spontanément dans le génome. Lorsqu’une mutation affecte des cellules de la lignée germinale d’un individu, alors elle devient transmissible à la descendance et peut être à l’origine de nouveaux allèles du gène muté. Les phénomènes de mutation ont été très étudiés chez la Drosophile (Drosophila melanogaster) et ont fourni de nombreux renseignements en particulier grâce aux gènes du développement. Les mutations peuvent affecter une plus ou moins grande partie du génome et peuvent avoir des conséquences plus ou moins importantes. On peut prendre comme exemple l’hémoglobine : Il s’agit d’une mutation ponctuelle se produisant sur une paire de bases dans le gène de la b globine. Elle sévit surtout en Afrique et chez les sujets noirs d’Amérique du nord. Elle fait partie dans ces régions des principales causes de mortalité. Le mode de transmission de la maladie est autosomique récessif. Les conséquences de cette mutation ponctuelle sont très importantes, mais les sujets hétérozygotes HbS/HbA sont relativement résistants au paludisme. L’allèle muté HbS est en fait un avantage sélectif à l’état hétérozygote mais une maladie grave à l’état homozygote. Cet avantage explique que l’allèle muté se soit considérablement répandu dans ces régions.
Les mutations contribuent à la diversité génétique. Une population relativement homogène du point de vue génétique serait moins adaptée aux modifications des conditions environnementales que ne l’est une population constituée d’individus génétiquement différents. Comme c’est le cas pour la drépanocytose, certaines mutations peuvent être bénéfiques et seront alors conservées au cours des générations. Les mutations sont induites par divers agents mutagènes de nature variable : le rayonnement solaire et en particulier les ultraviolets, des substances chimiques (5 bromo-uracile etc…). Tous ces facteurs du milieu extérieur conditionnent les mutations. Mais pour qu’une mutation puisse être conservée et transmise à la descendance, il faut qu’elle affecte les cellules de la lignée germinale. Ce principe est à la base de la théorie de la sélection naturelle et de l’évolution des espèces.
De plus l’évolution est assurée par un certain dynamisme de l’ADN, certains éléments peuvent se déplacer dans le génome, créer des copies… L’étude de ces capacités de l’ADN à évoluer et intégrer de nouvelles données constitue la base de la génétique moderne.
4.1. Certains gènes ont la possibilité de se déplacer
4.1.1. Réarrangements sporadiques
L’organisation du génome est relativement stable chez tous les individus d'une même espèce : l’ordre des gènes est le même. La recombinaison au cours de la méiose ne fait qu'échanger des segments homologues et ne contribue pas de ce fait à un réarrangement de l’organisation des gènes. Cependant, il existe des phénomènes de déplacement plus ou moins aléatoires de portions de chromosomes par l’intermédiaire de cassures accidentelles et de translocation sur un chromosome non homologue. Ceci est à l’origine de certaines trisomies (trisomie 21) oů le chromosome 21 peut être transloqué sur l’extrémité du chromosome 14 (Figure 17). Dans ce cas, il s’agit d’une fusion centrique : il y a fusion entre deux chromosomes acrocentriques, et les deux chromosomes sont alors impliqués dans leur intégralité à l’exception des bras courts, porteurs de portions satellites donc sans conséquence phénotypique. La fréquence de ces translocations est d’environ 1 pour 1000 naissances.
Un autre type de translocation est la translocation réciproque oů deux chromosomes s’échangent des portions d’ADN : il s’agit d’un échange mutuel. Il n’y a dans ce cas ni perte ni addition de matériel chromosomique. Les individus porteurs de ce type de translocation expriment un phénotype normal. Cependant, à la méiose, comme dans le cas précédent, cela peut aboutir à plusieurs possibilités de gamètes entraînant des ségrégation équilibrées ou déséquilibrées.
Les réarrangements sporadiques se produisent généralement au hasard tant en ce qui concerne les séquences que le moment oů elles surviennent. Ils génèrent souvent des mutations défavorables.
L'existence d'éléments d'ADN mobiles fut déduite en premier lieu par Barbara Mc Clintock au cours des années 1940 de ses d'études génétiques sur le maïs. Par la suite on a pu établir que de nombreux types d'éléments mobiles différents existent aussi bien chez les Procaryotes que chez les Eucaryotes. Les éléments mobiles sont de véritables perturbateurs génétiques, source de mutations diverses. Lorsqu'ils s'intègrent dans la séquence codante d'un gène ils en abolissent la fonction. Lorsque l'élément transposé aboutit dans une région adjacente à un gène, la régulation de ce dernier peut en être affectée de diverses façons. En fait, on sait à présent que nombre des mutations qui se sont révélées si utiles au début de ce siècle pour l'analyse génétique de la Drosophile sont dues à la transposition d'éléments mobiles (élément P). Même l'allèle responsable des pois ridés étudiés par Mendel résulte probablement de la transposition d'un élément mobile
L'ADN de l'élément transposable comprend un ou plusieurs gènes codant pour des protéines nécessaires à la transposition (transposases…). En deuxième lieu, de courtes séquences spécifiques, également requises pour la transposition, sont répétées aux deux extrémités de l'élément (pieds d’insertion) : ce sont les répétitions inverses gauche et droite. Ces éléments peuvent exercer des effets mutagéniques importants lorsqu'ils s'insèrent en de nouveaux sites.
Les rétrotransposons constituent un autre type d'élément mobile eucaryotique. La transposition de ces éléments implique la formation d'une copie d'ARN et la transcription inverse. Leur ADN comprend un segment central dont les gènes codent entre autres pour la transcriptase inverse requise pour la transposition. Dans certains rétrotransposons, le segment central est bordé par des répétitions longues de plusieurs centaines de paires de bases et de composition spécifique : les séquences LTR ou longues répétitions terminales (Long Terminal Repeat).
Ces rétrotransposons ressemblent à la forme désoxyribonucléique des rétrovirus, la forme que l'on retrouve insérée dans le génome de l'hôte. Le mécanisme de la transposition de ces éléments mobiles est très semblable à celui que les rétrovirus utilisent pour se reproduire. Cependant, contrairement aux rétrovirus, les rétrotransposons n'ont pas de forme extracellulaire, de sorte qu'ils ne sont pas infectieux.
Divers segments d'ADN dépourvus des caractéristiques structurales et des fonctions propres aux éléments mobiles ou rétrotransposons se déplacent aussi dans le génome. Contrairement aux éléments mobiles ils ont des tailles et des structures très variables. Parmi eux on trouve quelques pseudogènes. Certains pseudogènes dérivés des gènes codant pour divers ARN sont particulièrement abondants chez les Mammifères : un million de copies par génome n'est pas exceptionnel. L'intéressante famille de séquences itératives dispersées dans le génome humain (les séquences Alu : 5 à 10 % du génome humain) est un exemple de cette classe d'éléments. Leur présence peut conduire à d'autres réarrangements que la transposition puisque des répétitions non alléliques peuvent s'apparier et se recombiner, ce qui peut provoquer une perte ou un gain d’ADN. Les séquences Alu peuvent être à l’origine des familles de gènes (Figure 18) : les gènes A et B ont été dupliqués par un crossing over " illégal " et pourront être mutés pour devenir A’ et B’, gènes appartenant aux familles multigéniques de A et de B.
Outre les réarrangements sporadiques il s'en produit d'autres qui sont cette fois le fruit de processus normaux qui se déroulent dans certains types de cellules somatiques. Ces changements modifient l'expression du matériel génétique dans un ordre précis et suivant un programme déterminé.
4.1.2. Les réarrangements programmés
Les immunoglobulines sont les molécules du système immunitaire. Elles se présentent soit liées à la membrane cellulaire, soit libres (Figure 19) : anticorps circulants constitués de parties Fab (antigen binding) et Fc (Fragment cristallisable). La structure générale et les propriétés physico-chimiques de toutes les molécules d’anticorps sont relativement semblables. L’immunoglobuline G est le représentant caractéristique des immunoglobulines sécrétées par les plasmocytes. Elle est formée (Figure 20) de deux chaînes lourdes H (heavy chain) et de deux chaînes légères L (light chain). Chaque chaîne H est constituée de 3 domaines constants (CH1, CH2, CH3) et d’un domaine variable VH. Chaque chaîne L est constituée d’un domaine variable VL et d’un domaine constant CL.
La reconnaissance antigène-anticorps a lieu au niveau des parties variables de l’anticorps. La diversité des immunoglobulines est immense au niveau des zones variables. Ceci les rend aptes à fixer un grand nombre d’antigènes très différents (chaque anticorps ne reconnaît qu’un seul type d’antigène).
Si la synthèse de chacune des régions variables nécessitait la présence d’un gène de structure différent, cela supposerait la préexistence de plusieurs millions de gènes dans le génome, ce qui n’est pas le cas. Par contre, cette variabilité résulte de la recombinaison somatique d’un nombre limité de gènes (l’organisation de l’ADN est modifiée) dans un nombre pratiquement illimité de cellules différentes. Cette recombinaison a lieu pendant la maturation des lymphocytes.
Figure 21 : à l’extrémité 5’ du locus de l’Ig (immunoglobuline) sont situés les exons V1 à Vn codant pour la région variable V. Ils sont séparés par des séquences d’ADN non codantes. Les séquences L1 à Ln (leader) codent pour le signal d’initiation de la traduction et seront éliminées ultérieurement. Des segments des gènes D et J subissent une recombinaison les mettant bout à bout. Puis une recombinaison les rattache à un segment V. Dans ce seul phénomène de recombinaison-ligation, il y a plus de 25 000 combinaisons possibles ( 100 à 250 segments V, 12 segments D et 4 segments J) pour la formation d’une seule chaîne (ici une chaîne lourde).
4.2. Certains gènes sont à l’origine de cancers : virus et oncogènes
Le cycle cellulaire normal (Figure 22) conduit une cellule à caractère embryonnaire à des cellules différenciées incapables de se diviser et qui finissent par mourir (apoptose). Il existe un équilibre entre multiplication et mort cellulaire : il s’agit d’une régulation de la quantité de cellules. Lors de multiplications incontrôlées, cet équilibre est rompu et il y a apparition d’une tumeur. Cependant, les cellules tumorales sont généralement détruites par l’organisme ; mais parfois, dans le cas de la mutation de certains gènes, les cellules tumorales peuvent proliférer. Certains gènes sont impliqués dans le processus de tumorigenèse. Le contrôle du cycle cellulaire se fait par l’intermédiaire de différents facteurs : des facteurs de croissance (EGF, PDGF, IGF), leurs récepteurs, des anti-mitogènes (TGFb ) mais aussi par le MPF (maturation promoting factor) appelé aussi CDC (cell division control) constitué de protéines kinases (la famille des CDK = cyclin dependent kinase) associées à des cyclines. En 1993, on a découvert des protéines inhibitrices des CDK : les protéines CKI.
Un gène joue un rôle important dans le contrôle des cellules tumorales : le gène p53. Les mutations de ce gène font partie des causes génétiques fréquentes de différentes tumeurs malignes de l’Homme. Le gène p53 est situé sur le bras court du chromosome 17 et code pour une protéine nucléaire de 53 kDa, facteur de transcription. L’inactivation de p53 provoque une altération de la régulation du cycle cellulaire et le développement d’un cancer.
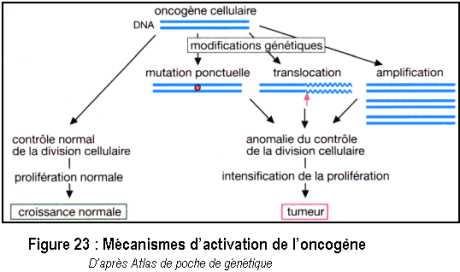
Certains gènes présents dans le génome et contrôlant des facteurs de croissance sont dits proto-oncogènes (à l’origine de cancer). Les oncogènes cellulaires ont été très conservés au cours de l’évolution en raison de leur fonction essentielle. L’activation des oncogènes cellulaires se fait par des modifications génétiques (Figure 23)
Certains virus transformants portent des oncogènes qui ont des homologues dans le génome cellulaire qui ne sont pas des oncogènes mais des proto-oncogènes. Figure 24 : différentes tumeurs induites par des oncogènes cellulaires (c-onc) et tumeurs induites par les oncogènes viraux homologues. C-src est un proto-oncogène bien connu, impliqué dans le sarcome aviaire. Le gène viral (v-src) contient certaines parties de c-src. Ce virus induit chez les poules une tumeur maligne : un sarcome, découvert en 1911 par Peyton Rous.
L’étude du fonctionnement des gènes, des virus et des bactéries a permis depuis les années 1970 de développer de nouvelles techniques regroupées sous le terme de " technologie de l’ADN recombiné ".
4.3. Le génie génétique et ses perspectives
En 1970, Temin et Baltimore découvrent l’existence d’une transcriptase inverse dans les rétrovirus. En 1974, on réalise les premiers gènes eucaryotes clonés dans des plasmides bactériens. Depuis, on a entrepris le séquençage des gènes, grâce à l’utilisation de l’ADN polymérase, puis surtout des enzymes de restriction. Les fragments de gènes obtenus sont marqués puis identifiés par électrophorèse sur gel. Des méthodes de plus en plus rapides ont été mises au point.
Les fragments d’ADN peuvent être multipliés. Le clonage de gènes peut se faire dans des bactéries grâce à l’insertion dans un vecteur de clonage : plasmide bactérien ou virus. La réplication se fait alors de façon autonome. D’autres types de vecteurs ont été mis au point, notamment des vecteurs synthétiques : ce sont les cosmides. Ils contiennent des caractères de plasmides ainsi que des caractères de bactériophages. Le clonage peut aussi se faire par PCR (Polymerase Chain Reaction) conçue en 1983 : il s’agit d’une méthode par amplification enzymatique. Ceci grâce à la découverte d’une ADN polymérase particulière : la Taq polymérase (issue de la Bactérie Thermus aquaticus) qui résiste à des températures allant jusqu’à 94°C. Ce qui permet l’automatisation des cycles nécessitant une dénaturation à haute température des doubles brins d’ADN (90°C)…
Le génie génétique permet aussi de réaliser des opérations de transgenèse, c’est-à-dire l’insertion d’un gène intéressant dans un génome. Cette technique est très utilisée dans les domaines médical, agro-alimentaire et industriel pour former des OGM (Organismes Génétiquement Modifiés). Citons par exemple la production d’insuline humaine ou d’hormones de croissance par E. coli, la production d’hémoglobine par le tabac, la création de végétaux résistants aux herbicides ou à meilleur rendement, l’obtention de bactéries capables de métaboliser le pétrole ou de vaches produisant du lait biopharmaceutique, etc.
Le séquençage du génome humain a été entrepris, et la cartographie complète est prévue pour 2002 à 2005. Le séquençage complet a été réalisé chez la levure et il apparaît que nous ne connaissons la fonction que d’une très faible partie du génome, même chez la levure. On peut donc se demander quels risques présentent pour le futur une telle facilité de modifier selon son gré le génome d’un organisme. Des problèmes de bioéthique sont d’ailleurs apparus, relancés par l’obtention récente de Mammifères à partir d’une cellule somatique (" clonage "), et ont fait l’objet d’avis du conseil consultatif national d’éthique. Rien ne semble arrêter la biotechnologie : empreintes génétiques, PCR quantitative en temps réel, thérapie génique, puces à ADN, etc.
Nos connaissances sur les génomes restant très limitées, établir une définition pour le gène demeure difficile mais la notion de gène a considérablement évolué depuis le début du siècle. Il n’y a aucune limite en vue aux découvertes à venir, tant intellectuelles que pratiques, concernant l’ADN et son expression ce qui laisse un champ d’étude très vaste à la recherche. On peut aujourd’hui obtenir un individu à partir de n’importe quelle cellule nucléée d’un organisme, mais certaines cellules subissent des réarrangement irréversibles au sein même de l’ADN (recombinaison somatique des lignées lymphocytaires) ou bien une perte à chaque division d’un fragment des télomères. Les questions prépondérantes actuellement concernent l’expression des gènes du développement et la nature du réseau d’événements régulateurs impliqués dans ce processus. Des découvertes fondamentales restent à faire et l’on peut se demander quels seront les prochains principes fondamentaux de la génétique à s’écrouler : la notion de gène reste donc en suspens…
Cordoliani (1994) Les acides nucléiques. Nathan Université, Paris.
Passarge (1995) Atlas de poche de Génétique. Flammarion Médecine-Sciences, Paris.
Lewin (1997) Gènes VI. Oxford University Press.
Alberts, Bray, Raff, Watson (1989) Biologie moléculaire de la cellule. Flammarion Médecine-Sciences, Paris.
Freifelder (1990) Biologie moléculaire. Masson, Paris.
Stryer (1992) La Biochimie. Flammarion Médecine-Sciences, Paris.
Kaplan, Delpech (1993) Biologie moléculaire et médecine. Flammarion Médecine-Sciences, Paris.
Suzuki, Griffith, Miller, Lewontin (1994) L’analyse génétique. De Boeck, Bruxelles.
Watson, Hopkins, Roberts, Steitz, Weiner (1989) Biologie moléculaire du gène. Inter-Edition, Paris.
Berg, Singer (1993) Comprendre et maîtriser les gènes, Le langage de l’hérédité. Vigot, Paris.
L’usine nouvelle, Biotech, Hors série (mars 1999)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}